Auf dieser Seite dokumentiere ich, wie ich mich auf das "Modul 162: Daten analysieren und modellieren" für die Lehrstelle vorbereite.
Dabei orientiere ich mich an den Lernzielen der Modulidentifikation auf der Webseite modulbaukasten.ch.
Mit Unterstützung von ChatGPT und verschiedenen Online-Ressourcen habe ich folgenden Lernplan erstellt:
Lernplan
Tag 1: Grundlagen der Daten und deren Strukturierung
Lernziele:
- Unterschied zwischen analogen und digitalen Daten verstehen
- Verschiedene Dateitypen und deren Eigenschaften kennen
- Unstrukturierte, semistrukturierte und strukturierte Daten unterscheiden
Lernschritte:
Datenarten und Speicherung
- Definition und Beispiele für analoge vs. digitale Daten
- Unterschied zwischen ausführbaren und nicht-ausführbaren Dateien
Strukturierung von Daten
- Was sind unstrukturierte, semistrukturierte und strukturierte Daten?
- Beispiele für jede Art von Daten
- Methoden zur Strukturierung unstrukturierter Daten
🔍 Übungsaufgaben
- Beispiele für analoge und digitale Daten notieren
- Daten aus dem Alltag in strukturiert, semistrukturiert oder unstrukturiert klassifizieren
Tag 2: Beziehungen zwischen Daten
Lernziele:
- Redundanzen und Inkonsistenzen vermeiden
- Beziehungstypen zwischen Tabellen verstehen (1:1, 1:m, n:m)
- Fremdschlüssel & Primärschlüssel erkennen
Lernschritte:
- Redundanzen vermeiden
- Warum sind Redundanzen schlecht?
- Beispiel für redundante Datenbanken
- Beziehungstypen
- 1:1-Beziehungen (z.B. ein Personalausweis gehört zu genau einer Person)
- 1:m-Beziehungen (z.B. ein Kunde hat mehrere Bestellungen)
- m:m-Beziehungen (z.B. Schüler besuchen mehrere Kurse, ein Kurs hat mehrere Schüler)
- Primär- und Fremdschlüssel
- Was ist ein Primärschlüssel?
- Wie verknüpft ein Fremdschlüssel zwei Tabellen?
🔍 Übungsaufgaben:
- Entwirf eine kleine Datenbank mit 3 Tabellen und bestimme Primär- und Fremdschlüssel
Tag 3: Geschäftsgrafiken – Visualisierung von Daten
Lernziele:
- Unterschiedliche Diagrammtypen und ihre Einsatzzwecke verstehen
- Kreis-, Balken-, Säulen-, Linien-, Flächen-, Netz- und Punktdiagramme kennen
- Excel nutzen, um Geschäftsgrafiken zu erstellen
Lernschritte:
- Mengenverhältnisse visualisieren
- Kreisdiagramme (Anteile in Prozent)
- Balken- und Säulendiagramme (absolute Zahlen vergleichen)
- Zeitverläufe darstellen – Liniendiagramme für Trends über die Zeit
- Flächendiagramme für kumulierte Werte und zum Aufzeigen von Abweichungen
- Netzdiagramme für multidimensionale Vergleiche
- Punktdiagramme für Streuungsanalysen
🔍 Übungsaufgaben:
- Wähle eine Datensammlung und erstelle zwei verschiedene Diagramme in Excel
Tag 4: Einführung in relationale Datenbanken
Lernziele:
- Was ist eine relationale Datenbank?
- Grundbegriffe: Entität, Attribut, Datentyp, Wertebereich
- Primärschlüssel vs. Fremdschlüssel
- Konsistenz & Redundanzfreiheit
Lernschritte:
- Grundlagen relationaler Datenbanken: Definition, Tabellen, Zeilen und Spalten
- Wichtige Konzepte: Entität, Attribut, verschiedene Datentypen
- Schlüssel in der Datenbank: Primärschlüssel vs. Fremdschlüssel
- Relationen zwischen Tabellen
🔍 Übungsaufgaben:
- Erstelle ein kleines Entity-Relationship-Modell (ERD) mit 3-4 Tabellen
Tag 5: Konzeptionelles Datenmodell
Lernziele:
- Anforderungen analysieren und in ein Datenmodell umwandeln
- ER-Diagramme erstellen
- Verknüpfungen zwischen Tabellen festlegen
Lernschritte:
- Anforderungen in Datenobjekte übersetzen
- Tabellenstruktur planen: Welche Attribute sind nötig?
- Beziehungen zwischen Tabellen definieren
- ERD zeichnen
🔍 Übungsaufgaben:
- Erstelle ein ER-Diagramm für eine Kursverwaltung
Tag 6: Logisches Datenmodell
Lernziele:
- Wechsel vom konzeptionellen zum logischen Modell
- Nutzung von Zwischentabellen bei m:m-Beziehungen
- Festlegung von Datentypen
🔍 Übungsaufgaben:
- Überarbeite dein ER-Diagramm aus Tag 5 und erstelle das logische Modell
Tag 7: SQL – Einführung und SELECT-Abfragen
Lernziele:
- Einführung in SQL und den SELECT-Befehl
- Daten mit WHERE, ORDER BY und GROUP BY filtern
- Aggregatsfunktionen (SUM, AVG, COUNT) nutzen
🔍 Übungsaufgaben:
- Formuliere eigene SELECT-Abfragen für eine Beispiel-Datenbank
Tag 8: Normalisierung – Datenbankoptimierung
Lernziele:
- Redundanzen und Anomalien vermeiden
- Verstehen der 1., 2. und 3. Normalform
- Datenbanken optimieren
🔍 Übungsaufgaben:
- Wandle eine unstrukturierte Tabelle in ein normalisiertes Schema um
Zusammenfassung
In diesem Lerntagebuch dokumentiere ich:
- Daten und ihre Struktur (Tag 1)
- Beziehungen zwischen Daten (Tag 2)
- Datenvisualisierung mit Geschäftsgrafiken (Tag 3)
- Relationale Datenbanken und ER-Diagramme (Tag 4-6)
- SQL-Grundlagen & SELECT-Abfragen (Tag 7)
- Normalisierung und Datenbankoptimierung (Tag 8)
24. Februar 2025 - Tag 1 - 4
Im Ramen des Modules habe ich mir als Fülldaten Daten eines Schiessclubs ausgedacht.
Folgende Themen habe ich heute bearbeitet und gelernt:
🔹 Tag 1: Grundlagen der Daten & Strukturierung
- ✅ Unterschied zwischen analogen & digitalen Daten (z. B. PDF vs. Buch)
- ✅ Dateiformate & Strukturierung (Textdateien, Bilder, Audiodateien, etc.)
- ✅ Unstrukturierte vs. strukturierte Daten
- Unstrukturiert: Freitext, Bilder, Social-Media-Posts
- Strukturiert: SQL-Datenbanken, Tabellen
🔹 Tag 2: Beziehungen zwischen Daten & Datenbanken
- ✅ Beziehungen zwischen Tabellen:
- 1:1-Beziehung: Ein Schütze ↔ eine Lizenz
- 1:m-Beziehung: Ein Verein ↔ viele Mitglieder
- m:n-Beziehung: Schützen ↔ Schiessstände
- ✅ Primär- & Fremdschlüssel → Wie Tabellen richtig verknüpft werden
- ✅ Zwischentabellen für m:n-Beziehungen
- ✅ Erste SQL-Abfragen mit
SELECT * FROM Tabelle
🔹 Tag 3: Geschäftsgrafiken & Datenvisualisierung
- ✅ Diagrammtypen & wann sie genutzt werden
- Balkendiagramm: Vergleich zwischen Schützen
- Punktdiagramm: Zusammenhang zwischen Alter & Trefferquote
- Kreisdiagramm: Altersverteilung von Schützen
- ✅ Daten für Diagramme aufbereiten & eigene Visualisierungen erstellen
🔹 Tag 4: Relationale Datenbanken & SQL-Abfragen
- ✅ Was ist eine relationale Datenbank?
- Mehrere Tabellen, verknüpft durch Primär- & Fremdschlüssel
- ✅ SQL-Statements & wichtige Befehle:
SELECT * FROM Tabelle;→ Alle Daten aus einer Tabelle abrufenJOIN→ Tabellen miteinander verknüpfenWHERE-Bedingungen → Bestimmte Daten filternORDER BY→ Ergebnisse sortieren
- ✅ Praxisbeispiel: SQL-Abfragen für Schützen & Schiessstände
- ✅ Logische Operatoren: Nutzung von
AND,OR,NOTfür komplexere Abfragen
🔹 Sicherheitsmechanismen & SQL-Schwachstellen
- ✅ Verständnis für SQL-Injection: Wie unsichere Eingaben zu Angriffen führen können
- Verwendung von Prepared Statements
- Einsatz von Input-Sanitization
- ✅ Warum Benutzerrechte & Zugriffskontrollen in Datenbanken wichtig sind
- ✅ Wie relationale Datenbanken sicherer gestaltet werden können
25. Februar - Repetition Tag 1-4, Tag 5-7 bearbeitet
Am Morgen habe ich mir die Zeit genommen, meine Webseite zu ergänzen und das gelernte zu repetieren.
Am Nachmittag habe ich den Lernplan weiter abgearbeitet und gelernt.
🔹 Tag 5: Konzeptionelles Datenmodell
- ✅ Was ist ein konzeptionelles Datenmodell?
- Zeigt die Datenstruktur & Beziehungen zwischen Tabellen
- Verwendet noch keine Datentypen oder konkrete Werte
- Wird als ER-Diagramm (Entity-Relationship-Diagramm) dargestellt
- ✅ Erstellung eines ER-Diagramms für die Schützen-Datenbank
💡 Enthält folgende Entitäten & Beziehungen:
[Schütze] 1 ---- (m) [Ergebnisse] (m) ---- 1 [Schiessstand]
| |
(m) (m)
| |
[Schützen_Waffen] --------------------- [Waffen]
➡ Wichtige Tabellen:
- Schützen – Enthält Personen
- Schiessstand – Enthält Orte
- Waffen – Enthält Waffenmodelle
- Ergebnisse – Speichert Punktzahlen, verknüpft Schützen & Schiessstand
- Schützen_Waffen – Zwischentabelle für m:n-Beziehung von Schützen & Waffen
🔹 Tag 6: Logisches Datenmodell
- ✅ Unterschied zwischen konzeptionellem & logischem Modell:
- Konzeptionelles Modell (Tag 5): ER-Diagramm, grobe Struktur der Datenbank, keine Datentypen
- Logisches Modell (Tag 6): Detaillierte Tabellenstruktur mit Datentypen & Zwischentabellen
- ✅ Wichtige Datentypen in SQL:
| Datentyp | Verwendung |
|---|---|
| INT | Ganze Zahlen (IDs, Alter, Punkte) |
| VARCHAR(X) | Zeichenketten (Namen, Wohnorte, Adressen) |
| DATE | Speichert ein Datum |
| BOOLEAN | Wahrheitswerte (Ja/Nein) |
✅ Finales logisches Modell für die Datenbank:
- Schützen – Enthält Name, Wohnort, Alter
- Schiessstand – Enthält Ort & Adresse
- Waffen – Enthält Waffenmodelle
- Schützen_Waffen – Verknüpft Schützen & Waffen (m:n)
- Ergebnisse – Speichert Punkte eines Schützen in einem Schiessstand
🔹 Tag 7: SQL – Einführung & SELECT-Abfragen
- ✅ Grundlegende SQL-Befehle:
| SQL-Befehl | Bedeutung |
|---|---|
SELECT * FROM Tabelle; |
Gibt alle Daten aus einer Tabelle zurück |
SELECT Spalte1, Spalte2 FROM Tabelle; |
Gibt nur bestimmte Spalten aus |
WHERE |
Daten nach Bedingungen filtern |
ORDER BY |
Ergebnisse sortieren (ASC/DESC) |
GROUP BY |
Daten gruppieren (z. B. Durchschnittswerte berechnen) |
HAVING |
Filter für Gruppenergebnisse setzen |
✅ Beispiel-Abfragen:
🔍 Alle Schützen aus Bern anzeigen:
SELECT * FROM Schütze WHERE Wohnort = 'Bern';
🔍 Schützen nach Alter sortieren:
SELECT * FROM Schütze ORDER BY Alter DESC;
🔍 Durchschnittliche Punktzahl pro Schiessstand:
SELECT Schiessstand_ID, AVG(Punkte) AS Durchschnitt
FROM Ergebnisse
GROUP BY Schiessstand_ID;
26. Februar - Praktische Repetition Tag 1-7 auf Linux mit MariaDB
Heute habe ich das bisher Gelernte praktisch angewendet. Dafür habe ich MariaDB auf meiner Kali-Linux-Maschine installiert und eingerichtet.
Als Erstes habe ich die Datenbank "SchiessDB" erstellt und die Tabellen "Schuetze", "Schiesstand", "Waffen", "Schuetzen_Waffen" und "Ergebnisse" angelegt.
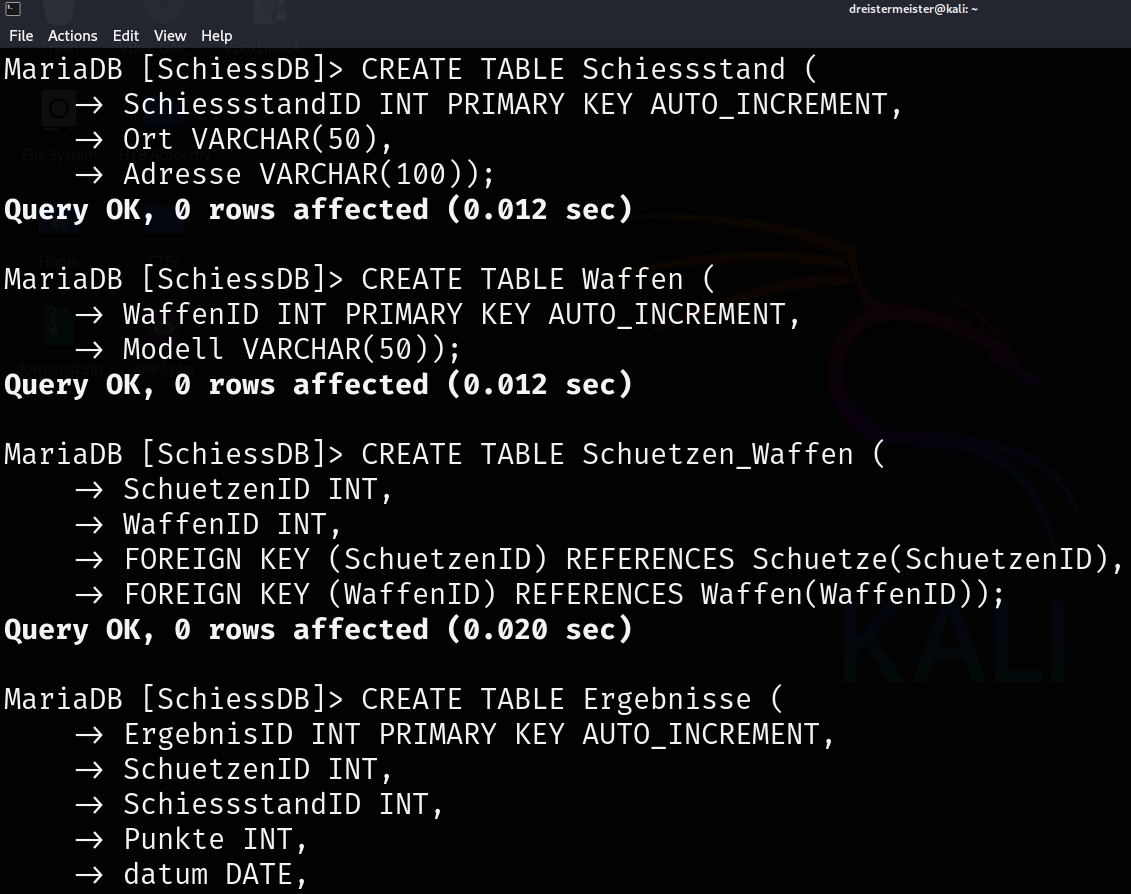
Danach habe ich die Tabellen mit Daten gefüllt, um eine realistische Datenbasis für SQL-Abfragen zu erstellen.
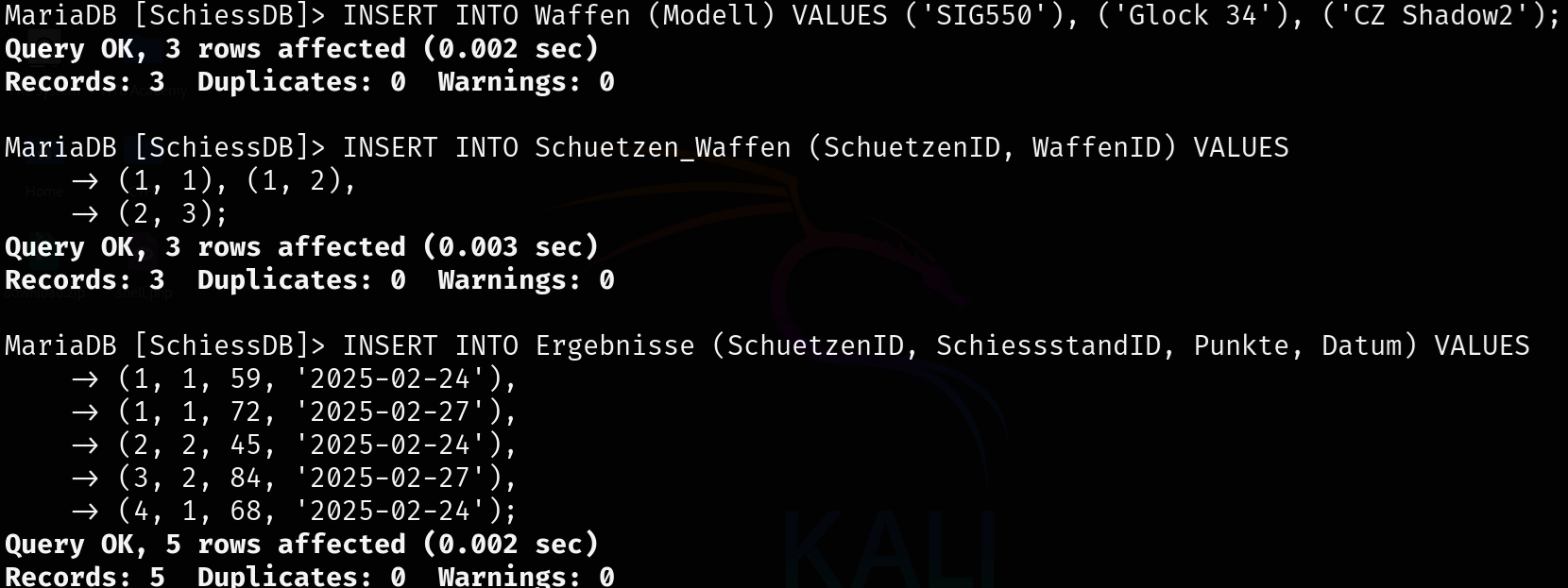
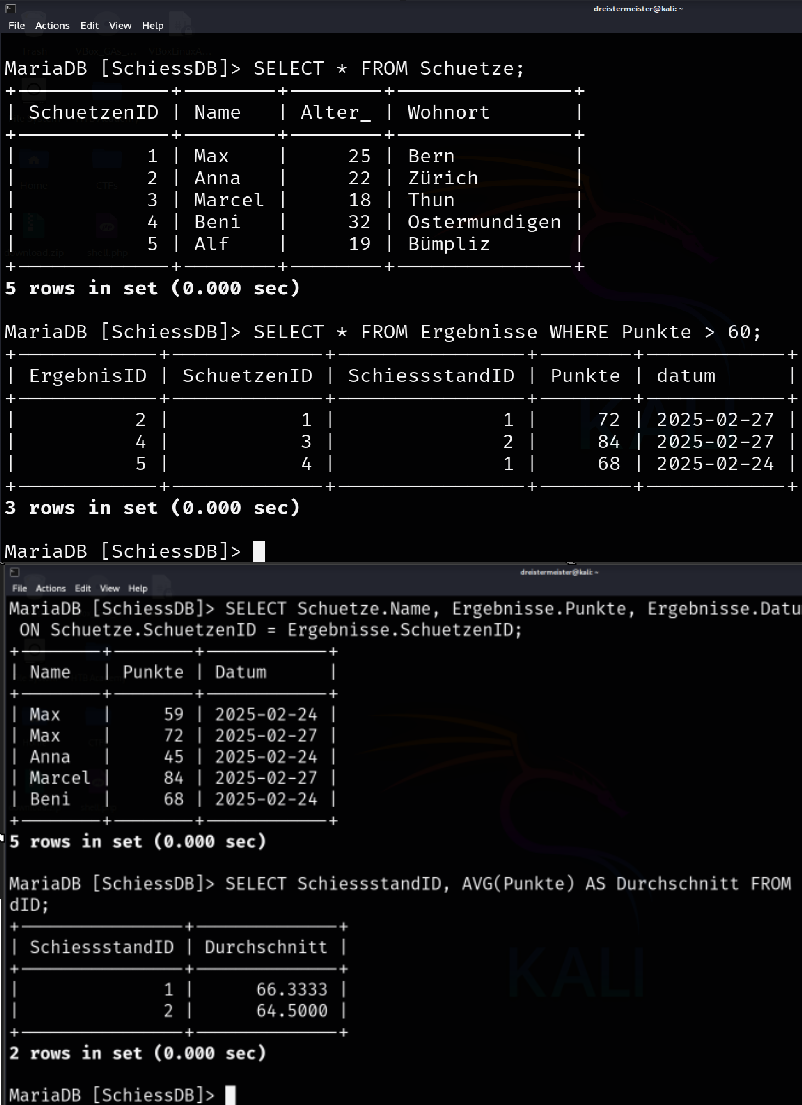
Schliesslich habe ich die erlernten SQL-Abfragen ausgeführt. Dabei habe ich WHERE-Bedingungen verwendet, um bestimmte Daten zu filtern, und mit JOIN mehrere Tabellen verknüpft.
28. Februar - Tag 8 - Anomalien - wie sie auftreten und wie man sie verhindern kann
Heute ging es um Anomalien, warum sie auftreten und wie man sie verhindern kann.
Es können drei Hauptanomalien in einer schlecht strukturierten Datenbank auftreten
- Update-Anomalien
- Insert-Anomalien
- Delete-Anomalien
Wenn ein Wert an mehrere Stellen existiert, muss er überall geändert werden
Man kann keine neuen Daten einfügen, ohne andere unnötigen Werte anzugeben.
Das kann bei Unnormalisierte Tabellen vorkommen.
Wenn ein Eintrag gelöscht wird, verschwindet auch die Information.
Zum Beispiel wenn ein Eintrag eines Schützen gelöscht wird, der in einem bestimmte Schiessclub trainiert,
kann es auch den Schiessclub löschen, wenn es kein anderer Schütze in der Datenbank gibt, der bei diesem Schiessclub trainiert.
Um das zu verhindern, kann man eine separate Tabelle für die Schiessclubs erstellen.
1. März - Repetition Modul-162
Heute habe ich das Modul-162 abgeschlossen und repetiert.
Dabei habe ich in meiner mit MariaDB erstellten Datenbank einige Abfragen repetiert.
Weiter geht es mit Modul 164 - Datenbanken erstellen und Daten einfügen.